
Вот уже более 30 лет прошло с момента выхода первого издания легендарной книги Фредерика Брукса ''Мифический человеко-месяц''. Немного перефразируя самого автора можно сказать так: ''Мифический человеко-месяц'' остается книгой, с которой все еще считаются в современной практике программирования. Ее читательская аудитория выходит за пределы сообщества программистов-разработчиков, она все еще порождает статьи, цитаты и письма, причем не только разработчиков программ, но и юристов, врачей, психологов, социологов. Эта книга, написанная 30 лет назад об опыте разработки программ, имевшем место 40 лет назад, остается актуальной и даже полезной.
Причина заключается в том, что ''история человечества - это пьеса, в которой сюжеты постоянны, сценарии медленно меняются с развитием культуры, а декорации меняются непрерывно. Поэтому в ХХ веке мы узнаем себя в Шекспире, Гомере и Библии. Поэтому в той мере, в какой ''МЧ-М'' написан о людях, он устаревает медленно>.
Автор излагает материал очень красочно, сочно, в целом абсолютно не возникает мысли о том, что читаешь техническую литературу. А насколько актуальны его мысли! Ведь мы и теперь любим свою профессию за те же самые радости, мы печалимся от тех же самых проблем, наши проекты все также погрязают в смоляных ямах, мы остаемся все такими же оптимистами и точно так же ошибаемся в своих оценках, надеясь ''что все будет идти хорошо''. Мы точно также осуществляем ''свои построения на основе чистого мышления'', точно так же робеем в своих оценках перед заказчиком и точно также читаем ''Мифический человеко-месяц'' в ''попытке проложить какие-то мостки через это болото''.
Я не хочу приводить весь перечень цитат, которые произвели на меня впечатление, потому что они займут с десяток страниц. Читать книгу очень интересно еще и по той причине, что на страницах автор заложил очень многое, что стало практикой программирования только сегодня. Так, автор описывает самодокументирование программ, которое позже мы увидим в работах МакКоннелла, Ханта и Томаса. Он говорит о важности слияния документации и файлов с исходными текстами. Это именно то, о чем говорит Мейер, и что мы видим в современных средах разработки. Брукс также поднимает вопросы сложности программных систем, которые вытекают из самой природы программного обеспечения, а также модель пошагового создания программных систем. Это именно те проблемы, которые в последствие неоднократно поднимут Буч, Джейкобсон и Рамбо в своих работах. Он уже тогда говорит о необходимости постоянного уточнения требований, о том, что пользователь не сможет, даже если захочет, предоставить полные и непротиворечивые требования, а также о пользе макетирования. Об этом позднее будут говорить Шаллоуей и Тротт и многие другие авторы.
Естественно есть и достаточное количество архаизмов. Все-таки, слишком многое изменилось в мире программного обеспечения за это время. Но это нисколько не раздражает и не расстраивает, а наоборот придает некоторый особый шарм чтению. Ведь только подумайте, книга основана на опыте разработки программ, имевшем место в 60-х годах, написана в середине 70-х, в главе 16 перепечатывается статья ''Серебряной пули нет'', датированная серединой 80-х, второе издание вышло в середине 90-х, а сейчас уже вторая половина следующего десятилетия. Таким образом, мы можем проследить историю отрасли за последние 40 лет!
В целом книга произвела на меня неизгладимое впечатление. И я всем и каждому советую ее прочитать. Но прочитать не просто так, в электронном виде или за бутылкой пива под телевизором, чтобы просто поставить галочку, что, дескать, все, я ее прочитал и могу с гордостью рассказывать об этом друзьям. Нет, эту книгу нужно читать в тихой обстановке, в удобном кресле, с карандашом за ухом и с запасом двух-трех десятков закладок, потому что количество полезных и интересных мыслей на строку текста - просто зашкаливает.





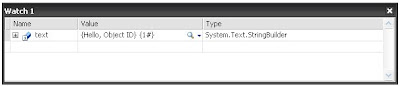
 Идентификатор объекта позволяет управляемому отладчику следить за объектом в любом месте кучи, независимо от контекста. Таким образом, если вам необходимо наблюдать локальную переменную из метода на двадцать элементов выше стека, создайте идентификатор объекта для этого объекта, и вы будете видеть реальное значение переменной независимо от того, где вы находитесь. Можно также создать идентификатор объекта для объекта в других потоках. Более того, вы увидите этот объект не зависимо от того, в каком поколении сборщика мусора он находится, а если он будет собран сборщиком мусора, то представление для этого идентификатора объекта станет недоступным. К сожалению нельзя добавить никакой дополнительной информации к идентификатору объекта и придется помнить, что означает порядковый номер каждого идентификатора, но т.к. слишком большое количество подобных объектов едва ли понадобиться, то и слишком большой проблемой это не будет.
Идентификатор объекта позволяет управляемому отладчику следить за объектом в любом месте кучи, независимо от контекста. Таким образом, если вам необходимо наблюдать локальную переменную из метода на двадцать элементов выше стека, создайте идентификатор объекта для этого объекта, и вы будете видеть реальное значение переменной независимо от того, где вы находитесь. Можно также создать идентификатор объекта для объекта в других потоках. Более того, вы увидите этот объект не зависимо от того, в каком поколении сборщика мусора он находится, а если он будет собран сборщиком мусора, то представление для этого идентификатора объекта станет недоступным. К сожалению нельзя добавить никакой дополнительной информации к идентификатору объекта и придется помнить, что означает порядковый номер каждого идентификатора, но т.к. слишком большое количество подобных объектов едва ли понадобиться, то и слишком большой проблемой это не будет.
{kind=link}
{kind=link}